

Why 3D Layout Is the Missing Link in AI Video Generation
The promise of AI video generation is exciting. Images that animate, scenes that build themselves, and stories that emerge from a text prompt. But anyone who’s tried to generate long-form content or multi-shot scenes knows the current limitations all too well: geometry that shifts, visual inconsistencies between frames, and an overall lack of directorial control.
These problems are more than technical nuisances. They’re creative dealbreakers.
- AI-generated scenes lack cross-shot consistency
- It’s difficult to precisely control camera motion in generated environments
- Manually building 3D scene models remains cost-prohibitive, especially in the film and television industry
That’s why, at Cybever, we believe the solution lies in structure – specifically, 3D layout.
We asked ourselves a simple question: Can 3D scenes bring the consistency and control that AI-generated video desperately needs?
To answer that, our research team developed 3DTown, a novel system capable of generating full 3D townscapes from a single top-down image. The research, recently published on arXiv, introduces a powerful approach to building richly detailed, semantically accurate 3D environments from a single 2D input.
Rather than relying on labor-intensive manual modeling, 3DTown leverages AI to interpret spatial relationships and construct complete 3D scenes populated with roads, buildings, and other environmental structures all while maintaining visual fidelity and geometric consistency. The result is a fully navigable, spatially coherent 3D environment that forms the ideal foundation for AI video generation.
This research isn’t just a technical milestone, it’s a paradigm shift. It allows us to treat layout not as an afterthought, but as a first-class creative tool. It’s the connective tissue between directorial vision and AI-driven rendering.
And with 3DTown’s speed and accuracy, the answer to our original question is now clear: Yes – 3D layout unlocks the control and consistency that AI video has been missing.
Here’s how we broke the challenge down:
- Start with 3D – When you anchor your scenes in geometry and layout, every frame knows where it is and what’s around it. This fixes temporal and spatial inconsistencies.
- Make it Fast – Our 3DTown system can generate complex 3D townscapes from a single map, reducing what used to take weeks of manual modeling to just minutes.
- Let AI Take It from There – Once a structured 3D scene exists, our AI tools can be layered on top to generate textures, fill in details, and even render final cinematic visuals on top of a consistent, layout-driven foundation.
This approach isn’t just about visual fidelity; it’s about creative freedom.
Directors can now sketch or block out a scene using rough 3D previz. That model becomes the canvas upon which AI renders multiple visual styles or edits. Directors can revise shots without re-rendering everything. Studios no longer need to pay artists to model complex scenes from scratch. Instead, 3DTown creates high-quality 3D scenes on-demand. Scenes remain consistent across different shots, camera angles, and edits. This keeps the spatial logic intact across wide shots, closeups, and moving cameras—essential for narrative clarity.
Results: How 3DTown Proves the Model Works
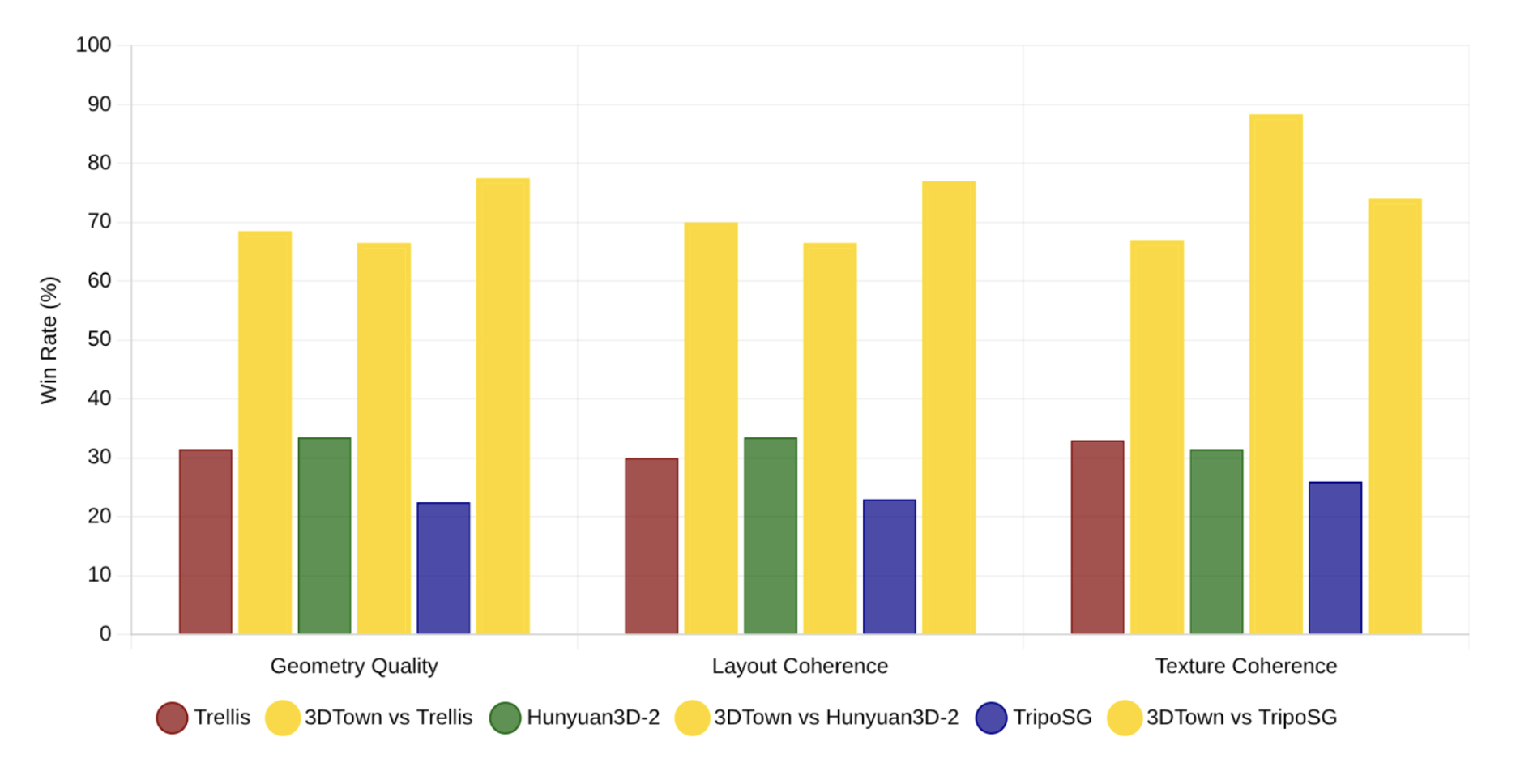
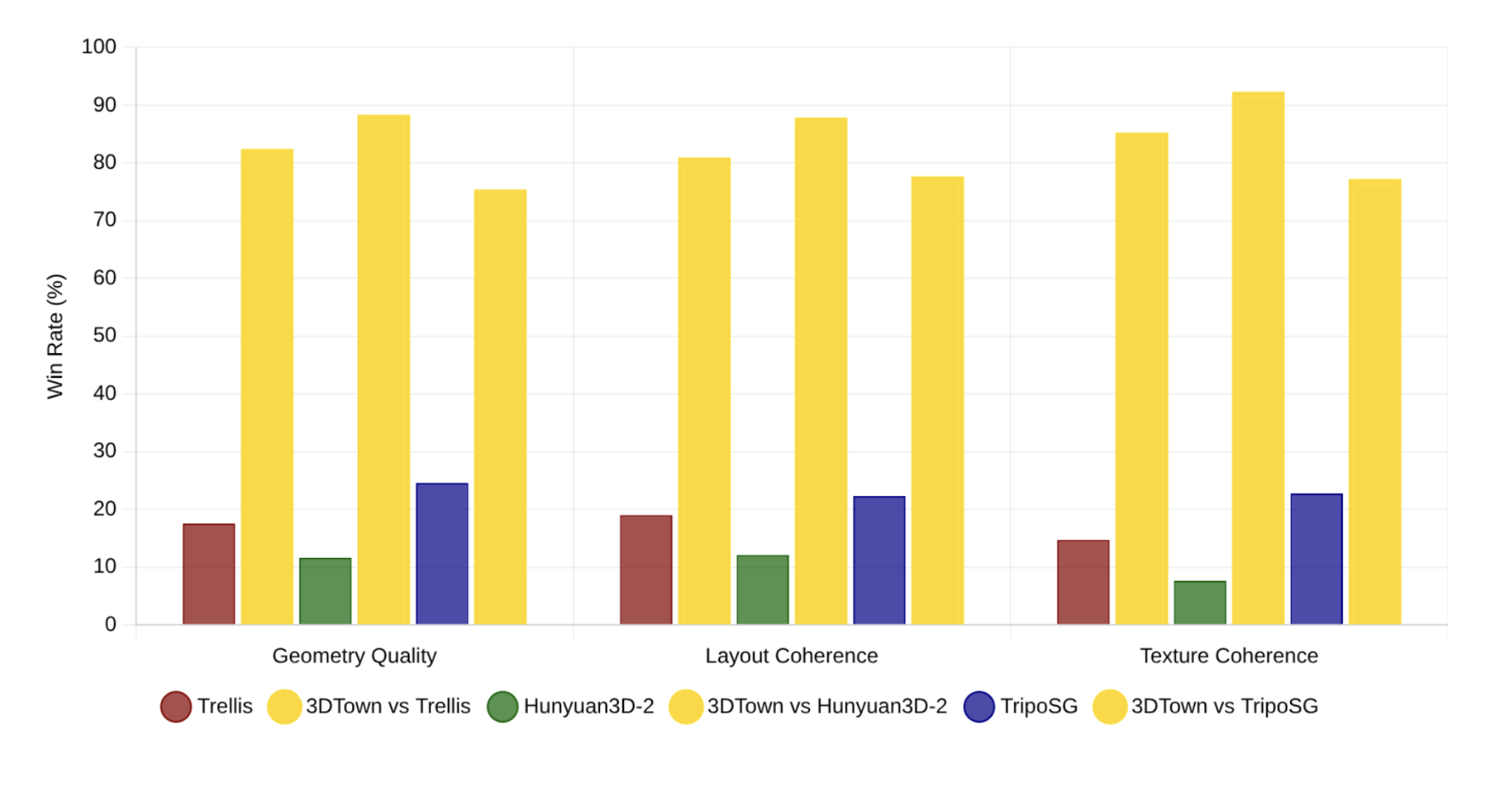
In our recent research, 3DTown showed significant improvements over state-of-the-art methods within the industry:
- 72% of human raters preferred our 3D reconstructions
- 75% said the environment matched expected road and building layouts
- 92% preference in GPT-4o-based evaluations for texture and structure fidelity
Human Preference Win Rate:
GPT4o-based Weighted Win Rate:
Qualitative comparisons:

These aren’t just academic wins. They translate directly into cleaner production pipelines, fewer revisions, and better outcomes for filmmakers and creators.
Ultimately, our goal is to empower a new kind of workflow where:
- Directors define shots through layout and motion, not final renders
- AI handles rendering style, lighting, and visual polish
- Artists and technicians collaborate over structured geometry, not flat pixels
This is how we turn AI into a creative amplifier – not a replacement.
In the entertainment industry, where visual continuity and directorial control are paramount, 3DTown introduces a zero-training-cost solution for previsualization. For research and industrial applications, it establishes a pipeline where spatial logic and visual fidelity are preserved from the start.
Sunnyvale, CA 94085, USA